Apache Camel Pulsar Function, Part 1
I recently came across an interesting article from DataStax about simplified, low-code friendly data piepelines with Pulsar Function and since I always wanted to learn a little bit more about Apache Pulsar and I’ve been working on something similar, I’ve started exploring how a Pulsar Function based on Apache Camel would look like.
Background
To get started, let’s have a basic understanding of Apache Pulsar and Apache Camel:
- Apache Pulsar is an open-source, distributed messaging and streaming platform built for the cloud.
- Apache Pulsar Functions is lightweight serverless computing framework enabling developers to process and manipulate data in real-time. The framework takes care of the underlying details of sending and receiving messages. You only need to focus on the business logic
- Apache Camel is an open-source integration framework that provides a wide range of connectors and patterns for integrating various systems and applications.
Goals
Provide a low-code, operational friendly way to deploy data transformation and routing pipelines on top of Apache Pulsar leveraging Apache Camel DSL
Pulsar Function Implementation
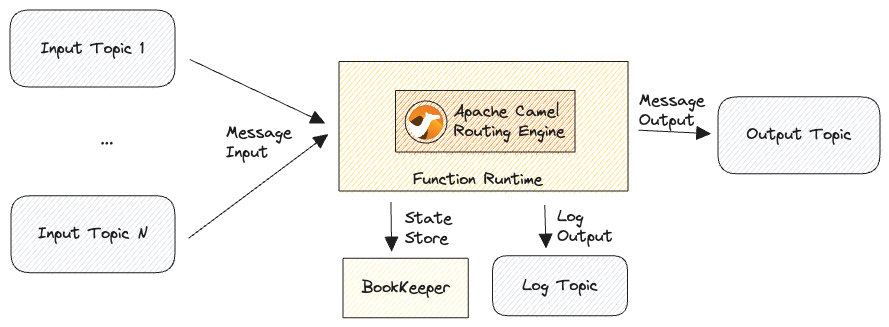
Pulsar functions can be developed in Java, Python, or Go and since Apache Camel is a Java framework, we can leveraging the Java SDK to embed a Camel Routing Engine in the Function Runtime:
In addition to the standard Java SDK, there is also an Extended SDK for Java which provides two additional interfaces to initialize and release external resources:
- With the
initializeinterface, you can initialize external resources which only need one-time initialization when the function instance starts. - With the
closeinterface, you can close the referenced external resources when the function instance closes.
In order to embed the Apache Camel in the function runtime, an instance of a CamelContext, must be created and since it is an heavyweight object, we can tie its lifecycle to the initialize and close so a CamelContext is created and started only once when the function instance starts and then it last for the entire lifecycle of the function.
At an high level, the implementation does the following tasks:
- Initialize and start a long running CamelContext instance when the function instance starts;
- Load the user defined processing steps defined using the Apache Camel YAML DSL;
- Wire the function input to the Camel’s Route and publish back the result to Pulsar depending on the configuration and routing decision;
- Close the CamelContext instance when the function instance closes.
Pulsar Function Configuration
The CamelFunction reads its configuration as YAML from the Function userConfig steps parameter.
As an example, a function configuration file would look like:
tenant: "public"
namespace: "default"
name: "content-based-routing"
inputs:
- "persistent://public/default/input-1"
output: "persistent://public/default/output-1"
jar: "build/libs/pulsar-function-camel-${version}-all.jar"
className: "com.github.lburgazzoli.pulsar.function.camel.CamelFunction"
logTopic: "persistent://public/default/logging-function-logs"
userConfig:
steps: |
- setHeader:
name: "source"
jq: '.source'
- choice:
when:
- jq: '.source == "sensor-1"'
steps:
- setProperty:
name: 'pulsar.apache.org/function.output'
constant: 'far'
- setBody:
jq:
expression: '.data'
resultType: 'java.lang.String'
- jq: '.source == "sensor-2"'
steps:
- setProperty:
name: 'pulsar.apache.org/function.output'
constant: 'near'
- setBody:
jq:
expression: '.data'
resultType: 'java.lang.String'
If you are familiar with the Apache Camel YAML DSL, you have probably noticed that the processing pipeline does not begin with from or route as you would probably expect and this is because the Camel Pulsar Function automatically create all the boilerplate that are required to wire the Camel’s routing engine to the Pulsar Function runtime. Beside this small difference, all the Apache Camel EIPs are available.
Access to contextual data
Some attributes of the function and record being processed are mapped to Camel’s Exchange Properties:
| Pulsar | Exchange Property Name |
|---|---|
| Function ID | pulsar.apache.org/function.id |
| Configured Output Topic | pulsar.apache.org/function.output |
| Record Topic | pulsar.apache.org/record.topic |
| Record Schema | pulsar.apache.org/record.schema |
| Record Key | pulsar.apache.org/record.key |
| Record Partition ID | pulsar.apache.org/record.partition.id |
| Record Partition Index | pulsar.apache.org/record.partition.index |
Access to Record data
Any Function’s Record property is mapped to an Camel’s Message Header
Routing
By default, the result of the processing pipeline is sent to the output topic defined in the function configuration, however it is possible to pick a different topic to apply a Content-Based Routing pattern as show in the example, by setting the exchange property pulsar.apache.org/function.output
Building and Deploying the Pulsar Function
- Clone the repository https://github.com/lburgazzoli/pulsar-function-camel
- Build the project by executing
./gradlew clean shadowJar - Deploy the generated function artifact (
build/libs/pulsar-function-camel-0.1.0-SNAPSHOT-all.jar) by following the tutorial
Conclusion
Event this is nothing more than a POC which requires more work to be production ready, I think that by combining Pulsar Function and Apache Camel’s integration capabilities, developers can build robust and efficient data pipelines with ease. The seamless integration, versatile transformation capabilities, flexible routing, and extensibility offered by this implementation make it an excellent choice for simplifying data pipelines within the Pulsar ecosystem.
To learn more about this implementation and explore its code, visit the GitHub repository
TODO
- Automatic data type conversion
- NAtive Support for Apache Pulsar in Apache Camel K
- Experiment with Pulsar Function Mesh